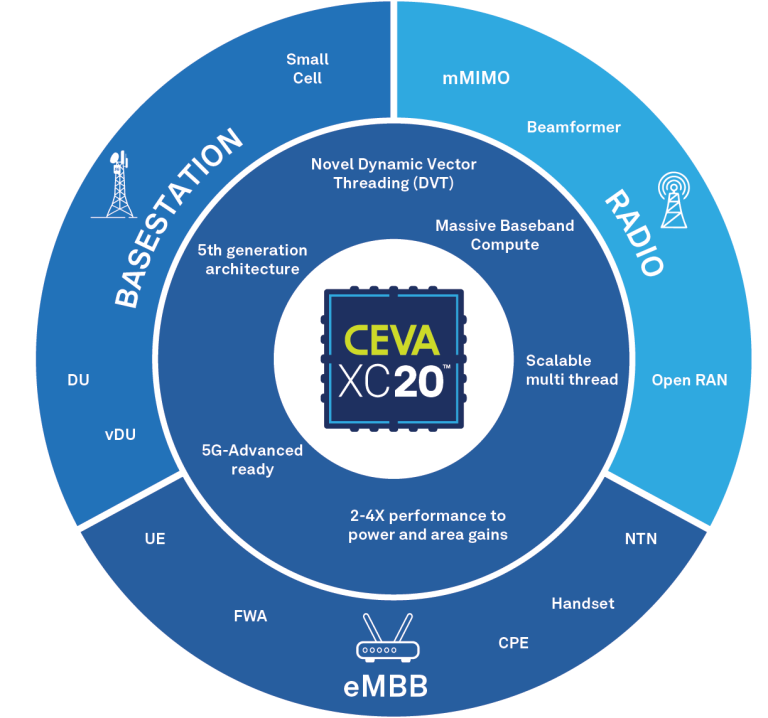
The CEVA-XC20 DSP architecture boosts computing power and reduces energy consumption through vector threading.
Now that 5G is here and growing, engineers have begun developing 5G Advanced, which promises more network computing power. 5G Advanced also paves the way for smaller devices and reduced energy use. To move the ASICS and SoCs that power this computing toward 5G-Advanced, CEVA has introduced its most powerful DSP core to date. The CEVA-XC20 architecture employs a novel Dynamic Vector Threading (DVT) scheme that supports hardware multi-threading.
 The company claims that DVT makes the CEVA-CX20 the first DSP core to have this multi-threading capability. Until now, multi-threading was found in general-purpose CPU architectures only. DVT enables optimal sharing of vector resources between different execution units that, according to CEVA, results in an unprecedented boost in vector utilization efficiency.
The company claims that DVT makes the CEVA-CX20 the first DSP core to have this multi-threading capability. Until now, multi-threading was found in general-purpose CPU architectures only. DVT enables optimal sharing of vector resources between different execution units that, according to CEVA, results in an unprecedented boost in vector utilization efficiency.
Using advanced memory hierarchy and the inclusion of protocol Layer 2 memory instances within the core, the CEVA-XC20 can support up to eight execution threads. Use cases include massive compute instances found in Virtual RAN (vRAN/vDU baseband processing) and large-scale Massive MIMO beamforming systems. Other use cases include baseband computing used in small cells, customer premises equipment (CPE), fixed wireless access (FWA), and enhanced mobile broadband (eMBB) devices such as smartphones.
The first DSP core based on the CEVA-XC20 architecture is the CEVA-XC22, which supports two execution threads with two independent scalar execution engines, each of which shares the core arithmetic vector resources using DVT. The CEVA-XC22 DSP brings more computing power to systems than CEVA’s previous generation CEVA-XC16 DSP. The CEVA-XC22 core offers a 2.5X improvement in efficiency (performance per watt and area) for essential 5G use cases and computation kernels. CEVA will also integrate the CEVA-XC22 its holistic baseband platforms, PentaG-RAN for cellular infrastructure and PentaG2-Max for high-performance mobile devices, where it will power CEVA’s heterogeneous compute platforms, including both DSPs and compute engine accelerators.
Following the CEVA-XC22, the CEVA-XC20 architecture will power the CEVA-XC24 and CEVA-XC28 DSPs, which will support four and eight execution threads, respectively. The latter will support 512 simultaneous vector Multiply Accumulate (MAC) operations. An advanced memory subsystem shared by all threads will bring scaling of execution threads, which significantly reduces the data bandwidth to external memory, thus improving latency. The CEVA-XC28 will bring a 4X performance gain over the previous generation, CEVA-XC16, while at the same time benefiting from the 2.5X power and area efficiency inherent from the CEVA-XC20 architecture.


Tell Us What You Think!